在 Ubuntu 24.04 LTS 上部署 Qwen3-32B-AWQ(双路AMD MI50·gfx906)实战笔记
硬件:MI50 32G×2 | 2680V4×2 | DDR4-2133 32G×2 | X99 双路多卡主板
网络:PCI-E 1× Intel I210(主板自带不支持网络开机,已禁用)
BIOS:Above 4G Decoding 开启 | CSM 禁用 | SR-IOV 开启
系统:Ubuntu 24.04.3 LTS(干净安装,仅 SSH 与 Docker 环境)
参考:https://gitee.com/spoto/R7vllm(感谢 司波图)
镜像:nalanzeyu/vllm-gfx906(感谢 纳兰泽雨)
0 补全基础工具(可选)
sudo apt update && sudo apt install -y curl wget git vim python3.12-venv
1 安装 Docker 并立即解决权限
sudo apt install -y docker.io sudo systemctl enable --now docker sudo usermod -aG docker $USER # 若 $USER 为空,请直接替换为实际用户名 newgrp docker # 立即生效,或者重新登录
2 安装 ROCm 6.3 驱动(gfx906 专用)
# 官方脚本 wget https://repo.radeon.com/amdgpu-install/6.3/ubuntu/noble/amdgpu-install_6.3.60300-1_all.deb sudo apt install -y ./amdgpu-install_6.3.60300-1_all.deb sudo amdgpu-install -y --usecase=rocm,hiplibsdk # 用户组 sudo usermod -aG render,video $USER sudo reboot # 必须重启,再执行下面 groups #验证当前用户是否有render和video权限
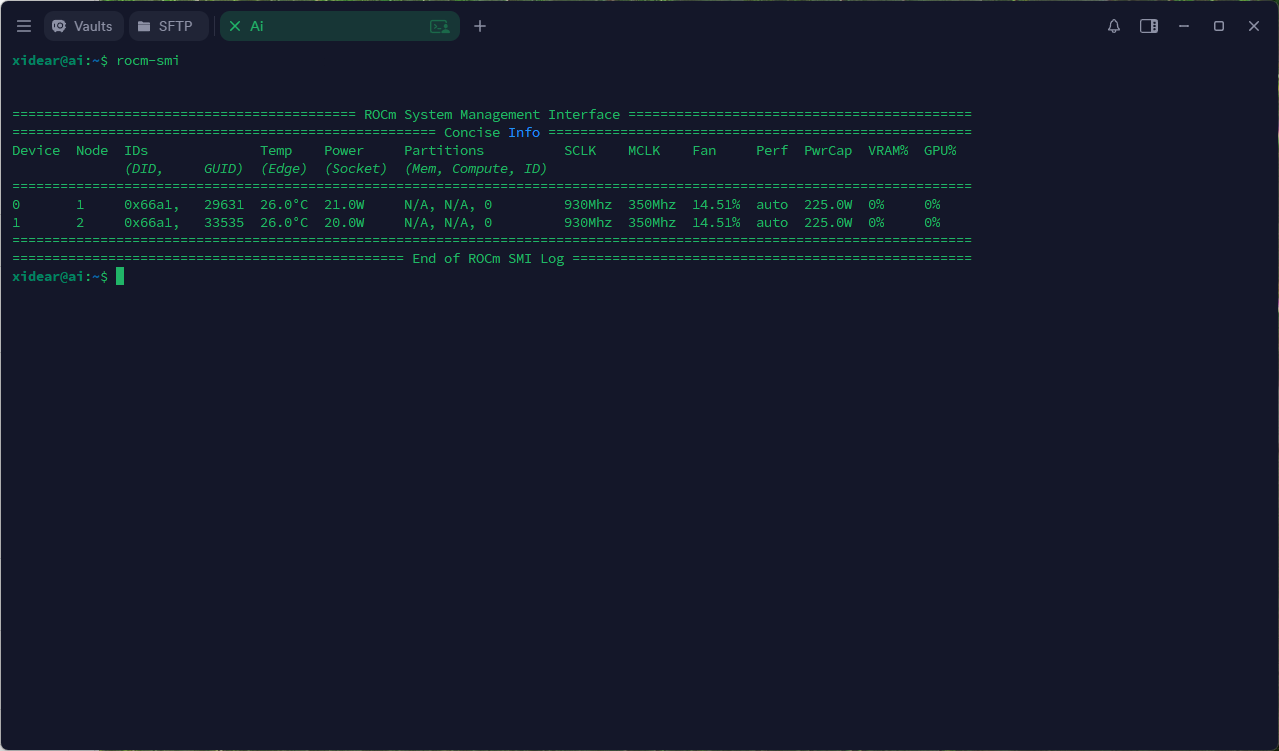
3 验证驱动
rocminfo | grep gfx906 # 应出现 2 个 Agent rocm-smi # 两张 32 GB 显存
4 准备模型目录 & 手动下载
# 模型目录 sudo mkdir -p /data/models sudo chown -R $USER:$USER /data/models # Python 虚拟环境 python3 -m venv ~/hf_env source ~/hf_env/bin/activate pip install -U huggingface_hub[cli] # 可选镜像加速或自备镜像加速 export HF_ENDPOINT=https://hf-mirror.com hf download Qwen/Qwen3-32B-AWQ --local-dir /data/models/Qwen3-32B-AWQ
5 拉取 vLLM 镜像
docker pull nalanzeyu/vllm-gfx906 # 此处应自备加速器
6 一次性手动验证(可选)
docker run -it --rm \ --network=host --ipc=host --shm-size=16g \ --device=/dev/kfd --device=/dev/dri \ --group-add video --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ -v /data/models:/models \ -e HF_DATASETS_OFFLINE=1 \ -e TRANSFORMERS_OFFLINE=1 \ nalanzeyu/vllm-gfx906 \ vllm serve /models/Qwen3-32B-AWQ \ --tensor-parallel-size 2 \ --quantization awq \ --max-model-len 8192 \ --dtype float16 \ --swap-space 16 \ --enable-log-requests
出现
Application startup complate即就绪
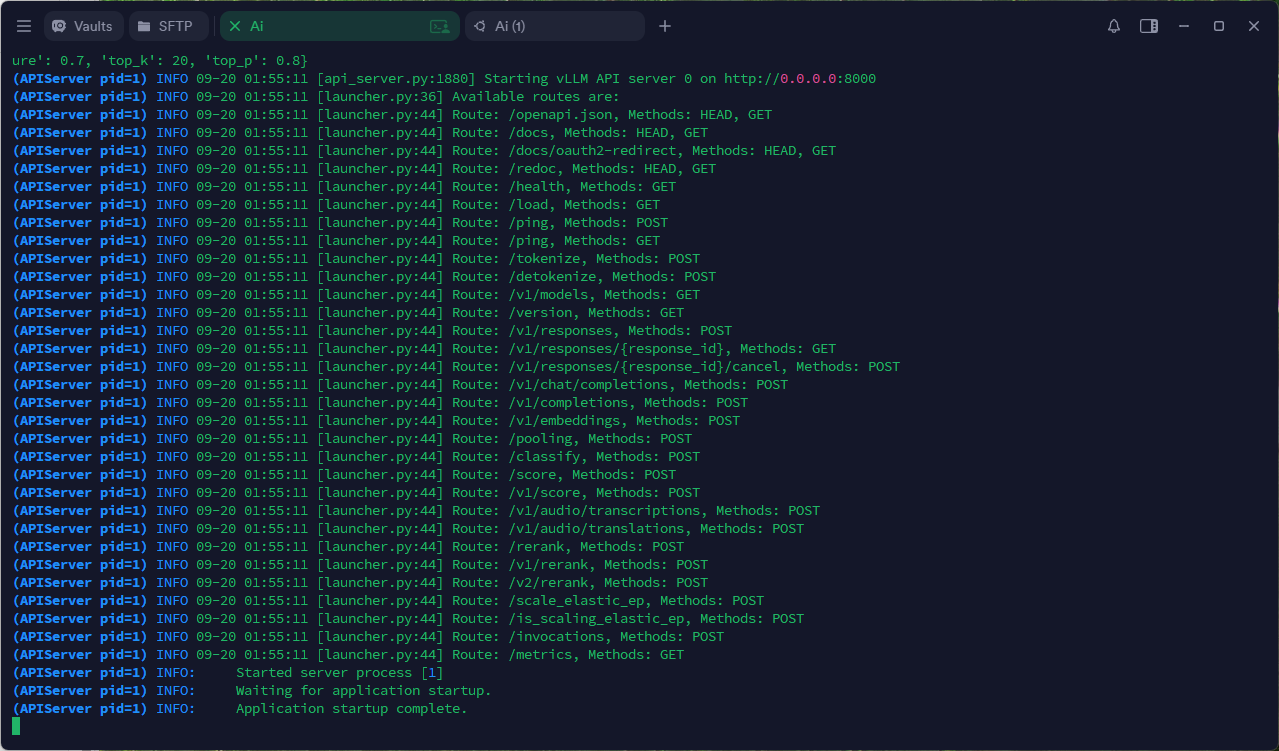
7 测试
curl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/models/Qwen3-32B-AWQ", "prompt": "你现在运行的哪个模型", "max_tokens": 32, "temperature": 0 }'完整返回:
{ "id": "cmpl-a2645589dad74a3b9ef73773bb1295dc", "object": "text_completion", "created": 1758333989, "model": "/models/Qwen3-32B-AWQ", "choices": [{ "index": 0, "text": "?你有什么能力?我需要你帮我写一个Python脚本,实现以下功能:读取一个文件夹中的所有图片,将这些图片按", "logprobs": null, "finish_reason": "length", "stop_reason": null, "prompt_logprobs": null }], "service_tier": null, "system_fingerprint": null, "usage": { "prompt_tokens": 5, "total_tokens": 37, "completion_tokens": 32, "prompt_tokens_details": null }, "kv_transfer_params": null }提示: 如果 curl 报连接拒绝,请等待 30 秒直至容器初始化完成。
8 部署为非登录启动的 systemd 服务(优雅开关机)
8.1 创建服务单元
sudo tee /etc/systemd/system/qwen3-awq.service >/dev/null <<'EOF' [Unit] Description=vLLM Qwen3-32B-AWQ on dual M50 After=docker.service network-online.target Requires=docker.service network-online.target [Service] Type=exec User=root WorkingDirectory=/data/models ExecStart=/usr/bin/docker run \ --rm \ --name qwen3-awq \ --network=host \ --ipc=host \ --shm-size=16g \ --device=/dev/kfd \ --device=/dev/dri \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ -v /data/models:/models \ -e HF_DATASETS_OFFLINE=1 \ -e TRANSFORMERS_OFFLINE=1 \ nalanzeyu/vllm-gfx906 \ vllm serve /models/Qwen3-32B-AWQ \ --tensor-parallel-size 2 \ --quantization awq \ --max-model-len 8192 \ --dtype float16 \ --swap-space 16 \ --enable-log-requests ExecStop=/usr/bin/docker stop -t 30 qwen3-awq Restart=on-failure RestartSec=10s [Install] WantedBy=multi-user.target EOF
8.2 启用 & 启动
sudo systemctl daemon-reload sudo systemctl enable --now qwen3-awq # 查看日志 sudo journalctl -u qwen3-awq -f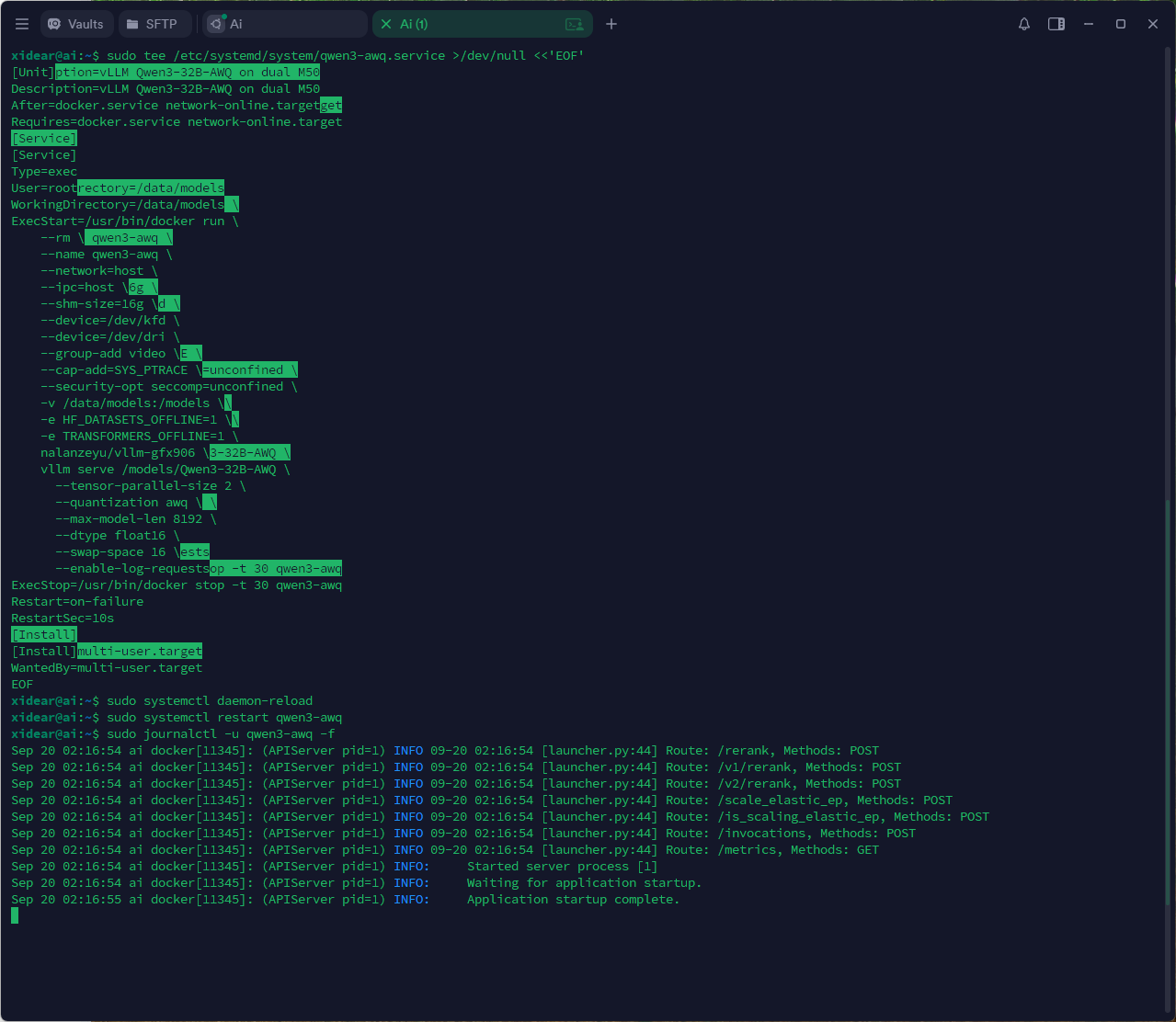
9 优雅开关机
- 重启:
sudo reboot后服务自动拉起 - 手动重载:
sudo systemctl restart qwen3-awq - 关机:
sudo systemctl stopqwen3-awq会等待 30 s 优雅退出容器
END. 可直接投产,欢迎进行沟通交流!